
Docker est un outil puissant de plus en plus utilisé par les dév et les ops surtout dans les entreprises qui ont adopté une démarche DevOps.
Cet outil permet en effet de tourner une application sur n’importe quel environnement de la même manière vu qu’il est agnostique par rapport au système.
La technologie Docker encourage le travail collaboratif entre développeurs et administrateurs et fournit un environnement qui réduit les silos entre les différentes équipes.
L’importance de Docker ne vient pas seulement de la technologie mais de son écosystème riche et de plus en plus accessible aux entreprises.
L’orchestration est l’une des technologies qui orbite autour de Docker, Google a créé Kubernetes, Amazon a créé ECS, Mesos a lancé Marathon et Docker inc. a lancé l’initiative Swarm.
L’avantage de Docker Swarm est qu’il est déjà intégré dans Docker par défaut.
Même s’il y a des efforts de la part de Google, Redhat, Docker inc., l’Open Container Foundation et d’autres organisations pour séparer entre Docker et Docker inc. (l’entreprise), Docker Swarm reste la technologie d’orchestration la plus accessible.
Par la suite nous allons découvrir comment créer une image, un conteneur Docker et un service puis comment utiliser Swarm pour le déployer.
1. Installation et Prérequis
Un conteneur Docker tourne de la même façon sur Ubuntu, Fedora ou n’importe quel autre OS par contre, la méthode de l’installation est différente.
Dans ce qui suivra, on va utiliser Ubuntu 16.04 comme système d’exploitation.
Pour l’infrastructure nous allons utiliser AWS mais vous pouvez utiliser n’importe quel autre fournisseur tant que les machines du cluster peuvent communiquer ensemble et tant que les contraintes des ports qu’on verra dans la suite est respectée.
Vous avez aussi le choix et créer votre cluster avec Docker Machine. Docker Machine est un outil développé par la communauté Docker qui sert à faire le provisionning des machines virtuelle de différents vendors cloud (AWS, GCE, DO) et même des machines locales avec VirtualBox.
Pour les installations à faire, on aura tout d’abord besoin d’installer Docker. Si vous avez une ancienne version de Docker installée, commencez par la désinstaller:
…
sudo apt-get remove docker docker-engine docker.io
…
Installez ensuite les paquets suivants :
…
sudo apt-get update
sudo apt-get install apt-transport-https ca-certificates curl software-properties-common
…
Importez les clés GPG :
…
curl -fsSL https://download.docker.com/linux/ubuntu/gpg | sudo apt-key add –
sudo apt-key fingerprint 0EBFCD88
…
Ajoutez les dépôts. Ceci dépend de l’architecture de votre machine :
- Pour amd64 :
…
sudo add-apt-repository \
« deb [arch=amd64] https://download.docker.com/linux/ubuntu \
$(lsb_release -cs) \
stable »
…
- Pour armhf :
…
sudo add-apt-repository \
« deb [arch=armhf] https://download.docker.com/linux/ubuntu \
$(lsb_release -cs) \
stable »
…
- Pour s390x :
…
sudo add-apt-repository \
« deb [arch=s390x] https://download.docker.com/linux/ubuntu \
$(lsb_release -cs) \
stable »
…
Finalement, installez la dernière version de Docker :
…
sudo apt-get update
sudo apt-get install docker-ce
…
2. Architecture de Docker Swarm
Avant de commencer à créer ou manipuler des clusters, comprendre le fonctionnement et l’architecture de Docker Swarm est essentiel pour la suite.
Depuis la version 1.12, une évolution remarquable a été ajoutée à Docker: le mode Swarm.
Ce mode a introduit de nombreuses fonctionnalités qui ont résolu quelques difficultés.
Docker Swarm sert l’API Docker standard de sorte que tout outil qui communique déjà avec un démon Docker peut utiliser Docker Swarm pour s’adapter de manière transparente à la scalabilité : Dokku, Docker Compose, Krane, Flynn, Deis, DockerUI, Shipyard, Drone, Jenkins ..etc.
Le mode Swarm permet en plus de gérer des réseaux, des volumes et des plugins avec des commandes Docker standard. Son « scheduler » comporte des filtres utiles comme les tags de noeuds et des stratégies comme binpack.
Swarm est production-ready et, selon Docker inc, il a été testé pour scaler jusqu’à 1 000 nœuds et cinquante mille 50 000 conteneurs sans dégradation de performance.
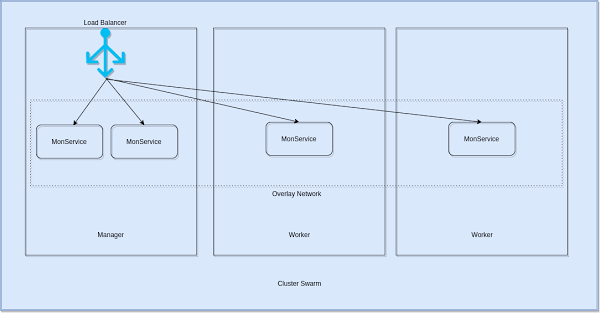
Un cluster Swarm est composé de managers et de workers.
Les managers sont les leaders du cluster et c’est eux qui sont responsables de l’exécution des algorithmes d’orchestration.
L’une des best practices à retenir est que le nombre de managers ne doit jamais être un nombre pair mais plutôt impair: 1, 3, 5 .. etc. Ceci garantira une bonne exécution de l’algorithme Raft qui est indispensable pour la disponibilité d’un cluster et qui utilise le vote.
Raft offre une manière générique de distribuer une machine d’état à travers un cluster de systèmes informatiques, en s’assurant que chaque noeud du cluster accepte les mêmes séries de transitions d’état.
Il a un certain nombre d’implémentations de référence open-source, avec des implémentations de spécifications complètes dans Go, C ++, Java et Scala.
Raft atteint un consensus par l’intermédiaire d’un leader élu. Un serveur dans un cluster Raft est soit :
- un leader
- un candidat
- ou un disciple Swarm qui utilise des heartbeat pour informer les machines d’un cluster de la présence d’un leader, si au bout d’un certain temps le leader ne fait aucun signe, un processus d’élection s’organise et les noeuds voteront pour le premier candidat qui a envoyé un heartbeat.
Pratiquement, si on prend l’exemple d’une application qu’on déploie sur un cluster formé par 1 manager et 2 workers, on crée et lance le service depuis le manager, on le configure, re-configure et scale aussi depuis la même machine.
Dans l’exemple où on scale notre application (qu’on appelle MonService) à 4 instances, l’orchestrateur s’occupe de les distribuer d’une manière équilibrée sur l’ensemble du cluster.
Le manager est celui qui doit recevoir toute requête interrogeant notre application depuis l’extérieur. C’est l’algorithme du load balacing interne au mode Swarm qui permet la découverte des instances distribuées dynamiquement sur l’ensemble du cluster et puis la distribution de la charge sur ces instances là.
Ce load balancing se base sur un réseau overlay spécial appelé « ingress ». Lorsqu’un noeud Swarm reçoit une requête sur un port public, cette requête part d’un module appelé IPVS. IPVS conserve une trace de toutes les adresses IP participants à ce service, sélectionne l’un d’entre elles et envoie la demande sur le réseau ingress.
Notre service (MonService) aura par défaut un « user-defined network » (un overlay network) et si un autre service devra communiquer avec le nôtre il doit être attaché à ce réseau overlay.
3. Création d’un Cluster Swarm
Pour la suite, on utilisera 3 machines dont 1 manager et 2 workers.
Les machines doivent pouvoir communiquer ensemble. Les ports 2377 (TCP), 7946 (TCP et UDP) et 4789 (TCP et UDP) doivent être accessible. Docker doit être installé sur les 3 noeuds.
La première étape à suivre est d’initialiser le manager :
…
docker swarm init –advertise-addr <node_ip|interface>[:port]
…
Pratiquement, si notre interface eth0 a 138.197.35.0 comme adresse IP, on lancera le cluster comme suit :
…
docker swarm init –force-new-cluster –advertise-addr 138.197.35.0
….
Il faut adapter l’adresse IP à ce que vous avez sur votre manager.
La dernière commande va afficher une commande qui permet à un worker de rejoindre le cluster :
…
docker swarm join \
–token SWMTKN-1-5b54vz0sie1li0ijr0epkhyjvmbbh2pg746skh8ba5674g1p6x-cmgrvib1disaeq08x8a5ln7zo \
138.197.35.0:2377
…
Cette commande doit être exécutée depuis les 2 workers, vous pouvez ainsi voir les 2 worker depuis votre machine manager en tapant :
…
docker node ls
…
4. Créer et Déployer un Service sur un Cluster Swarm
Après la création du cluster, on pourra passer à la création d’un service et puis son déploiement.
Notre service se basera sur un fichier Dockerfile simple :
…
FROM alpine
ENTRYPOINT tail -f /dev/null
…
Ce fichier crée une boucle infinie qui va tourner une fois le conteneur est lancé. C’est pour cette raison que je lui ai donné le nom “infinite”.
On doit builder ce Dockerfile :
…
docker build -t eon01/infinite .
…
On pourra par la suite créer le service qui correspond à ce build :
…
docker service create –name infinite_service eon01/infinite
…
Pour vérifier si le service a été créé, on peut utiliser la commande :
…
docker ps
…
5. Scaler un Service sur Swarm
On un service qui a été lancé depuis notre manager, mais par défaut il y aura une seule instance qui va être déployée. L’une des forces du mode Swarm n’est pas simplement la scalabilité mais la simplicité de l’exécution de cette opération. Si le service est fonctionnel, on a qu’à exécuter :
…
docker service scale infinite_service=2
…
Cette commande va créer une autre instance à part celle qui a déjà été créée au début.
Pour scaler jusqu’à 50 instances du même service, on utilise la même commande :
…
docker service scale infinite_service=50
…
Conclusion
L’écosystème Docker est composé d’un ensemble d’outils riches mais les orchestrateurs ont le plus grand poids dans le monde des conteneurs.
Docker Swarm est un orchestrateur qui vient par défaut avec Docker, son utilisation n’est pas compliqué, il n’a sûrement pas les mêmes caractéristiques que Kubernetes ou un autre orchestrateur mais il a ses points forts.
L’évolution de Docker et Docker Swarm est dynamique et rapide ce qui constitue un point fort pour ce produit même si quelques avis considèrent que ces changements successifs apportés à cet outil doivent être plus étudiés et mieux standardisés.



