
1. Introduction
SEM3D est un logiciel de haute-fidélité qui résout des problèmes élastoacoustiques en 3D grâce à la méthode des éléments spectraux (SEM) basé sur des éléments finis linéaires et hexaédriques quadratiques. La méthode SEM exploite une approximation polynomiale d'ordre élevé pour atteindre une grande précision de l'approximation numérique. SEM3D est largement utilisé pour simuler les séismes. Il est conçu pour prédire le champ d'ondes sismiques en 3D caractérisant des scénarios de tremblements de terre complexes, depuis la faille jusqu'au site d'intérêt, généralement dans des régions de 100 km x 100 km (voir Figure 1).
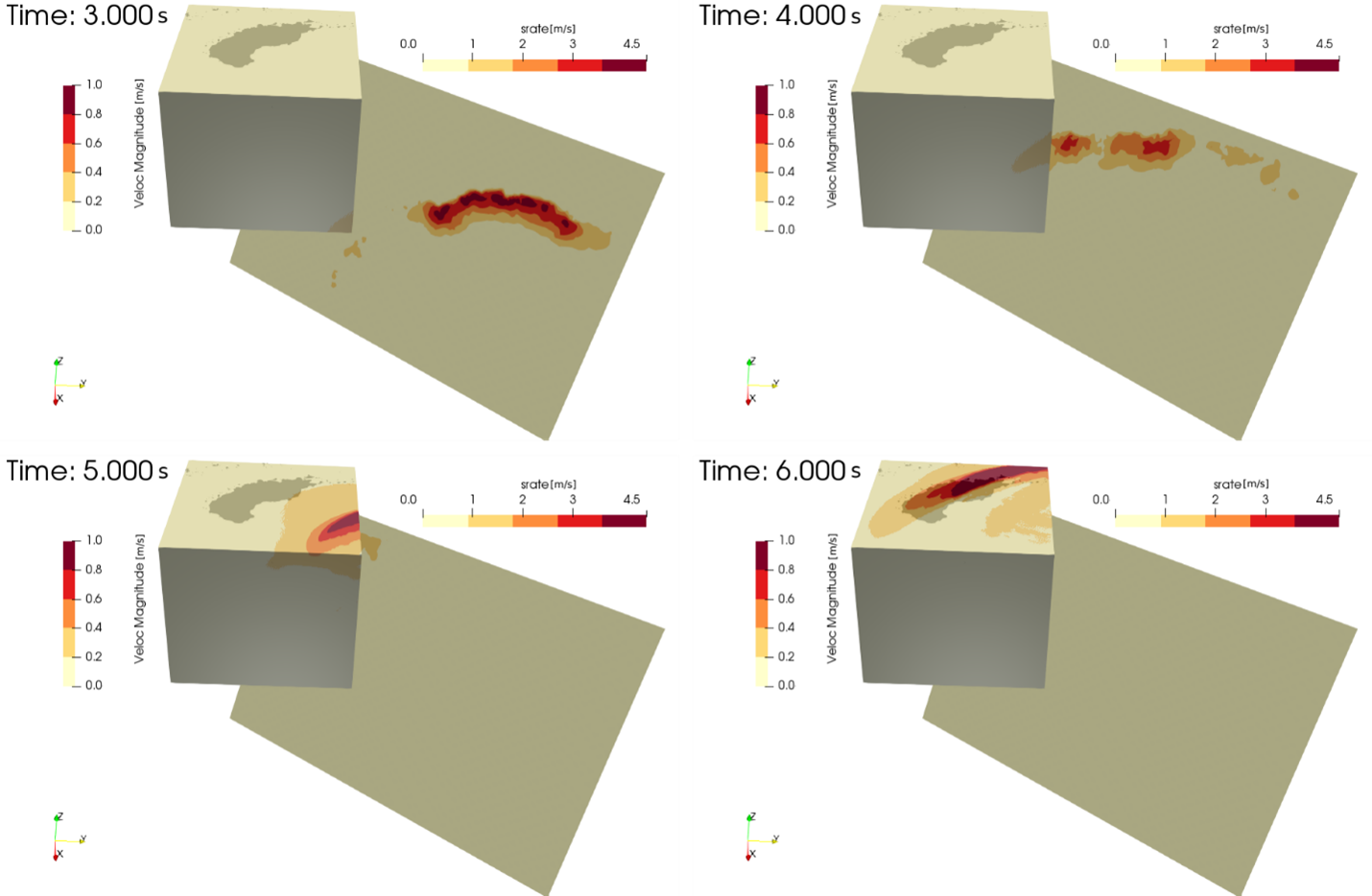
Figure 1: Captures d'écran d'une simulation SEM3D de l'événement sismique à Argostoli (Touhami et al.2022) 1.3 · 1010 dofs ; 0-10 Hz Argostoli earthquake [5]. ≈20 h wall-time - 4000 MPI cores @Occigen (3333 days CPU time)
Le développement de SEM3D a commencé il y a plus de 10 ans et a été réalisé en collaboration par :
- Institut de Physique du Globe de Paris
- Commissariat à l'énergie atomique et aux énergies alternatives
- CentraleSupélec
- Centre national de la recherche scientifique.
Le code source de SEM3D se trouve ici (Touhami 2022).
Au fil des années, SEM3D a été soigneusement optimisé pour tirer parti des supercalculateurs modernes et a été largement testé sur les supercalculateurs nationaux français (TIER1) tels que CINES Occigen et IDRIS Jean-Zay. En particulier, les principaux efforts ont été consacrés à :
- Mettre en place une vectorisation explicite (jusqu'à AVX 512).
- Démontrer une scalabilité faible et forte jusqu'à 4 096 cœurs et au-delà.
- Développer une entrée/sortie HDF5 parallèle.
Ce document présente les résultats du benchmark SEM3D sur les instances AMD de GCP. Étant donné que le compilateur d'Intel est largement utilisé dans les environnements de calcul intensif, nous avons également souhaité évaluer les performances du compilateur AMD par rapport à celui d'Intel.
L'objectif de cette étude est de :
- Observer et comprendre le comportement de SEM3D, et comparer les performances des compilateurs Intel (ICC) et des compilateurs C/C++ et Fortran optimisés d'AMD (AOCC) sur les instances AMD de GCP.
- Montrer les performances et la scalabilité de SEM3D sur une machine virtuelle (VM) basée sur AMD sur la solution GCP.
Après une brève description de l'application et des instances, la méthodologie et les exécutions seront décrites. L'analyse des résultats sera ensuite fournie.
2. Description du benchmark
Cette section présente l'approche technique adoptée pour le benchmark, en commençant par une brève description des deux cas tests. Elle décrit également l'infrastructure et les compilateurs utilisés pour ce travail.
2.1 Cas tests
L'approche la plus couramment adoptée pour évaluer les performances des logiciels de calcul intensif est de tester leur scalabilité faible et forte. Dans les deux cas, nous comparons les performances obtenues avec différents nombres de nœuds de calcul. Dans le cas de la scalabilité forte, le même problème est utilisé pour toutes les mesures. Dans le cas de la scalabilité faible, à mesure que nous doublons le nombre de nœuds, la taille du problème est également doublée.
Dans ce travail, nous avons adopté un ordre polynomial de 4, correspondant à 5 points d'intégration Gauss–Lobatto–Legendre (GLL) par direction, pour un total de 125 points GLL par hexaèdre.
2.1.1 Scalabilité faible
Le premier cas d'utilisation consiste en un domaine parallélépipédique simple de dimensions 1200 m x 1200 m x 1500 m. Il a été utilisé pour étudier la scalabilité faible où la charge de travail du CPU reste constante avec une valeur pratique de 32000 éléments et un temps de simulation de 0,1 seconde.
Les exécutions de scalabilité faible ont été réalisées de 1 à 900 cœurs.
2.1.2 Scalabilité forte
Un deuxième modèle, plus réaliste, basé sur 1256000 éléments, a été utilisé pour l'analyse de la scalabilité forte.
Un temps de simulation de 0,5 seconde a été utilisé pour toutes les exécutions, démarrant de 112 (un nœud) jusqu'à 4032 cœurs (36 nœuds).
2.2 Architecture Cloud
Une collection de scripts Bash a été développée pour gérer le processus. Ces scripts lancent un groupe d'instances du nombre de nœuds requis, configurent l'environnement, effectuent le calcul, puis détruisent le groupe. Les scripts qui gèrent l'infrastructure sont basés sur gcloud.
Le script de démarrage configure essentiellement la clé SSH et installe les packages.
Ensuite, le premier nœud monte le disque persistant, qui est utilisé pour stocker les données d'entrée et l'application, et exporte les données via NFS pour les rendre accessibles aux autres nœuds. Les autres nœuds effectuent ensuite le montage NFS. À la suite de cela, la tâche est initiée, et les résultats sont collectés.
Une fois toutes les exécutions terminées, les données de sortie sont récupérées, et les scripts de post-traitement sont exécutés.
2.2.1 Description de l’instance C2D
Les instances utilisées dans ce travail sont de type c2d-standard-112.
Ce type d'instance optimisée pour le calcul est basé sur le processeur AMD EPYC de 3e génération, comprend 112 vCPUs, a une capacité de 896 Go de mémoire et une bande passante de sortie par défaut de 32 Gbps.
2.3 Compilateurs et bibliothèques
L'application a été initialement développée pour les processeurs Intel et a été rigoureusement testée avec le compilateur et les bibliothèques Intel. Dans cette étude, notre objectif était d'évaluer la facilité de porter un code de la suite Intel à celle d'AMD et de comparer les performances des deux architectures. Nous avons compilé SEMD3D et comparé les performances obtenues avec ces deux configurations.
SEM3D dépend de HDF5. Ainsi, pour être cohérent, ce dernier a également été compilé dans le cadre de ce projet. La version 1.14.0 de HDF5 a été utilisée.
2.3.1 Compilateur Intel :
La suite Intel est composée des trois éléments suivants :
- Intel oneAPI compiler version 2023.2.0 : le cœur du compilateur
- MKL version 2023.0.2 : les bibliothèques mathématiques
- Intel MPI version 2023.2.0 : l'implémentation MPI d'Intel
Voici comment HDF5 a été compilé avec le compilateur Intel :
./opt/intel/oneapi/setvars.sh
export CC=icc
export F9X=ifort
export FC=ifort
export CXX=icpc
./configure --prefix=${build} --enable-fortran --enable-cxx --enable-shared
make
make install
2.3.2 Compilateurs AMD pour C/C++ et Fortran
Cette étude a utilisé les trois éléments suivants :
- AOCC version 4.0.0 : le compilateur
- AOCL version 4.0 : la bibliothèque mathématique
- OpenMPI version 4.1.4 : l'implémentation MPI
Voici comment HDF5 a été compilé avec le compilateur AOCC :
/opt/AMD/aocc-compiler-4.0.0/setenv_AOCC.sh
export CC=clang
export F9X=flang
export FC=flang
export CXX=clang++
export FCFLAGS='-fPIC'
./configure --prefix=${build} --enable-fortran --enable-cxx --enable-shared
sed -i 's/wl=""/wl="-Wl,"/' libtool
3. Résultats et Analyse
Les résultats des tests sont présentés ci-dessous. Ils consistent à reporter le calcul central du processus de résolution du problème par itération en fonction du nombre de cœurs pour les binaires SEM3D compilés avec les compilateurs Intel et AOCC.
La scalabilité faible se réfère à un scénario où la taille du problème évolue avec le nombre de cœurs.
En revanche, pour la scalabilité forte, les tailles de problème sont maintenues constantes à mesure que le nombre de processeurs augmente.
3.1 Scénario de Scalabilité Faible
Tout d'abord, la figure 2 met en évidence la différence de performances entre les compilateurs Intel et AOCC. En effet, nous pouvons constater que, pour ce cas de test, AOCC est entre 1,30 et 1,36 fois plus performant.
Ensuite, la Figure 2 montre également que les deux compilateurs présentent le même comportement. Le temps de calcul reste constant sur plusieurs nœuds, tandis que l'utilisation de moins d'un nœud complet augmente le temps de calcul. Cela peut indiquer un surcoût de la communication inter-processeur, des problèmes d'équilibrage de charge, ou le fait que le caching n'est pas pleinement utilisé.
Cependant, le premier suggère que le temps d'exécution de l'application reste constant, car la taille du système et la taille du problème augmentent de manière proportionnelle.
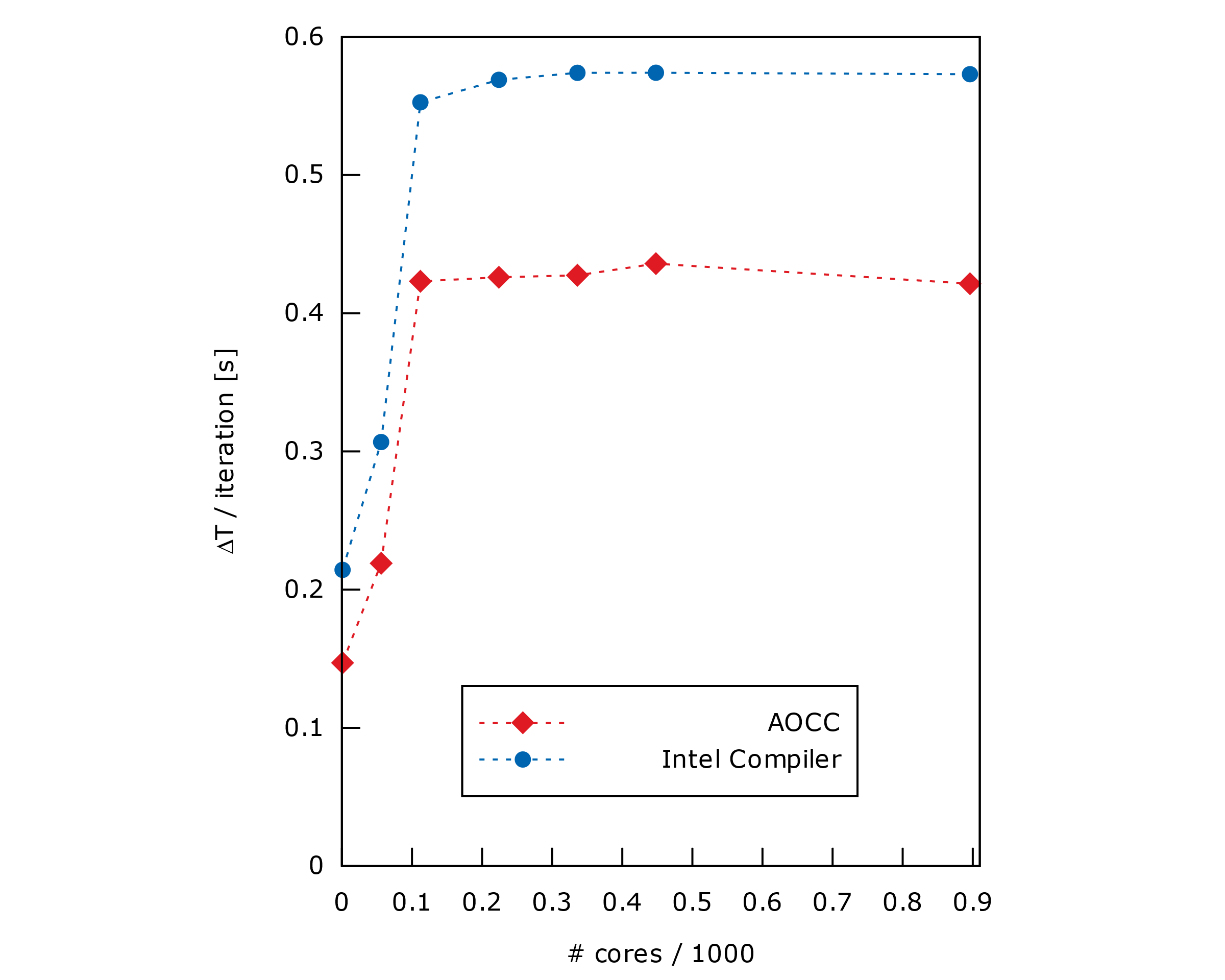 Figure 2. Scalabilité faible pour les compilateurs Intel et AOCC (le plus bas le meilleur). Les ordonnées représentent le temps d'exécution total divisé par le nombre d'itérations.
Figure 2. Scalabilité faible pour les compilateurs Intel et AOCC (le plus bas le meilleur). Les ordonnées représentent le temps d'exécution total divisé par le nombre d'itérations.
Cela indique que SEM3D utilise efficacement les ressources de calcul accrues pour gérer des problèmes de plus grande taille, en maintenant le temps de résolution stable.
Autrement dit, puisque le coût de calcul dépend de la taille, cela signifie qu'à nombre d'éléments par CPU constant, le prix de la simulation est proportionnel à la précision requise.
3.2 Scénario de Scalabilité Forte
La Figure 3 représente le calcul clé du processus de résolution du problème par itération, multiplié par le nombre de cœurs, en fonction du nombre de cœurs.
Comme pour le premier système, AOCC est environ 1,67 fois plus performant.
De plus, les résultats montrent un comportement constant lors de l'utilisation de plusieurs nœuds.
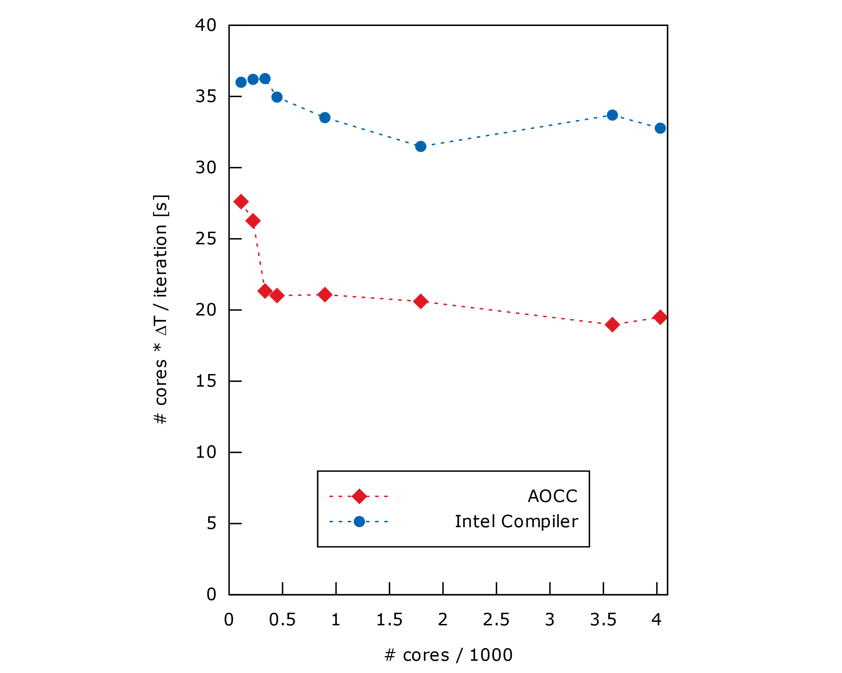 Figure 3. Scalabilité forte pour les compilateurs Intel et AOCC (le plus bas le meilleur). Les ordonnées représentent le temps d'exécution total divisé par le nombre d'itérations multiplié par le nombre de cœurs.
Figure 3. Scalabilité forte pour les compilateurs Intel et AOCC (le plus bas le meilleur). Les ordonnées représentent le temps d'exécution total divisé par le nombre d'itérations multiplié par le nombre de cœurs.
Étant donné que le coût de calcul dépend du nombre de processeurs demandés pour la simulation, nous constatons que le coût de la simulation reste constant à mesure que le nombre de cœurs augmente. En pratique, cela permet aux utilisateurs d'obtenir des résultats beaucoup plus rapidement sans augmenter la consommation de ressources, que ce soit en termes d'énergie ou d'argent.
4.Conclusion et perspectives
5. Bibliographie
Ce document est la propriété de la société Aneo et ne peut en aucun cas être distribué à des personnes ou organisations tierces sans l’accord écrit de la société Aneo



