
Lilia ZIANE KHODJA (ANEO), Damien DUBUC (ANEO), Florent DE MARTIN (BRGM), Faïza BOULAHYA (BRGM), Steve MESSENGER (AWS), Gilles TOURPE (AWS), Diego BAILON HUMPERT (Intel), Loubna WORTLEY (Intel)

Le Bureau de Recherches Géologiques et Minières (BRGM) est le premier établissement public français pour les applications des sciences de la Terre à la gestion des ressources de la surface et du sous-sol dans une perspective de développement durable. Dans le cadre de partenariats avec de nombreux acteurs publics et privés, il se concentre sur la recherche scientifique, fournissant des informations scientifiquement validées pour soutenir l'élaboration des politiques publiques et la coopération internationale.
À cette fin, le BRGM a besoin de réaliser des simulations de calcul haute performance (High Performance Computing « HPC ») pour évaluer diverses grandeurs d'intérêt pour les politiques publiques, telles que l'élévation du niveau de la mer, l'aléa sismique ou la vulnérabilité des bâtiments. Par exemple, des scénarios de tremblement de terre à grande échelle, basés sur la physique, sont réalisés pour évaluer l'aléa sismique et quantifier leur degré de confiance par rapport aux incertitudes épistémiques ou aléatoires. Cette approche nécessite d'énormes ressources informatiques qui sont généralement fournies par des infrastructures nationales (Tier-1) ou européennes (Tier-0).
Cet article fait le point sur les performances d'EFISPEC3D, l'application HPC du BRGM pour le calcul de scénarios de séismes sur AWS.
EFISPEC3D est un programme informatique scientifique qui résout les équations tridimensionnelles du mouvement à l'aide d'une méthode spectrale continue d'éléments finis de Galerkin. Le code est parallélisé à l'aide de l'interface de transmission de messages (MPI).
"EFISPEC3D est optimisé pour s'étendre sur plusieurs milliers de cœurs pour une taille de maille standard (par exemple, 2 millions d'éléments spectraux) grâce à son schéma de communication non bloquant et à ses trois niveaux de communicateurs MPI. Les résultats de performance présentés ci-après, qui utilisent un maillage de 1 906 624 éléments spectraux répartis sur 27036 cœurs physiques, montrent une mise à l'échelle équitable jusqu'à 70 éléments spectraux par cœur physique". EFISPEC3D est utilisé dans différents domaines, tels que l'évaluation des risques sismiques pour les installations industrielles critiques comme les centrales nucléaires, le calcul urgent, l'analyse de sensibilité via l'apprentissage automatique ou la propagation des ondes sismiques dans un milieu géologique complexe (par exemple, les vallées sédimentaires, les volcans, etc.)
EFISPEC3D est développé par le Bureau de Recherches Géologiques et Minières (BRGM) depuis 2009 en collaboration avec Intel Corp, l'Institut des Sciences de la Terre (ISTerre), et le Laboratoire d'Informatique Fondamentale d'Orléans (LIFO). Il a fait et fait encore partie de plusieurs projets de recherche financés par l'Agence Nationale de la Recherche (ANR).




Différentes vues du maillage du cas test n°2 conçu avec deux niveaux de raffinement : un de 315 m à 105 m et un de 105 m à 35 m afin de tenir compte des longueurs d'onde sismiques mesurant au moins 35 mètres. À l'intérieur du contour du bassin, le maillage est affiné sur une profondeur constante qui inclut le point le plus bas du bassin sédimentaire étudié. Le maillage contient 7 053 889 éléments hexaédriques non structurés (environ 1,4 milliard de degrés de liberté) sur lesquels la forme faible des équations du mouvement est résolue.
Différentes vues du maillage du cas test n°2 conçu avec deux niveaux de raffinement : un de 315 m à 105 m et un de 105 m à 35 m afin de tenir compte des longueurs d'onde sismiques mesurant au moins 35 mètres. À l'intérieur du contour du bassin, le maillage est affiné sur une profondeur constante qui inclut le point le plus bas du bassin sédimentaire étudié. Le maillage contient 7 053 889 éléments hexaédriques non structurés (environ 1,4 milliard de degrés de liberté) sur lesquels la forme faible des équations du mouvement est résolue.
Résultats
L'intérêt ici est de présenter l'utilisation des services AWS pour réaliser les simulations de prédiction du BRGM. Une simulation typique d'une durée d'environ 300 jours sur un seul cœur sera exécutée en 25 min sur AWS Cloud, en utilisant 27k cœurs physiques et sans hyper-threading.
AWS a mis à disposition plusieurs types d'instances Amazon Elastic Compute Cloud (Amazon EC2) basées sur Intel. Les 27k cœurs utilisés pour ce rapport de performance sont basés sur les instances c5n.18xlarge avec le processeur Intel® Xeon® Platinum 8000 Series (Skylake-SP) avec une fréquence de 3.5GHz ainsi que les instances m5zn.12xlarge alimentées par des processeurs personnalisés Intel® Xeon® Scalable de 2ème génération (Cascade Lake) à 4.5GHz. Les instances Amazon c5n et m5zn utilisent toutes deux Elastic Fabric Adapter (EFA) pour prendre en charge la communication entre les nœuds. Les deux types d'instances ont été choisis parce qu'ils offrent un rapport coût/performance différent.
| Instance | Processor | vCPU | RAM (GiB) | Networks (Gbps) |
| c5n.18xlarge | Skylake-SP | 72 | 192 | 100 |
| m5zn.12xlarge | Cascade-Lake | 48 | 192 | 100 |
Simulations de mise à l'échelle forte
Dans les premières expériences, nous testons la forte mise à l'échelle de l'application EFISPEC3D sur les instances AWS c5n.18xlarge et m5zn.12xlarge.
Le script suivant décrit un exemple de script batch pour effectuer une simulation sur 16 384 cœurs d'instances c5n.x18large :
#!/bin/bash
#SBATCH --account=account-strong-scaling-16384
#SBATCH --job-name=string-scaling-16384
#SBATCH --partition=batch-c5n
#SBATCH --hint=nomultithread
#SBATCH --mem-per-cpu=2048M
#SBATCH --nodes=456
#SBATCH --ntasks=16384
#SBATCH --ntasks-per-node=36
#SBATCH --ntasks-per-core=1
#SBATCH --output=string-scaling-16384-%x_%j.out
ulimit -s unlimited
mpiexec.hydra -n 16384 /fsx/applications/EFISPEC3D-c5n-18xlarge/TEST-1-STRONG-SCALING/EFISPEC3d-ASYNC/bin/efispec3d_1.1_avx.exe
Un maillage d'environ 2 millions d'hexaèdres, soit environ 77 Go de RAM, est analysé sur un seul cœur physique jusqu'à 27036 cœurs physiques.
| Number of cores | Number of instances | Average number of hexahedra per physical core | Average RAM per core (Mo) | Elapsed time for initialization |
| 1 | 1 | 1906624 | 77145.555 | 181.56 s |
| 32 | 1 | 59582 | 2420.925 | 29.62 s |
| 64 | 2 | 26480 | 1077.098 | 25.91 s |
| 128 | 4 | 13240 | 539.555 | 28.89 s |
| 256 | 8 | 6620 | 270.070 | 39.14 s |
| 512 | 15 | 3530 | 144.265 | 37.57 s |
| 1024 | 29 | 1826 | 74.870 | 61.39 s |
| 2048 | 57 | 930 | 38.236 | 97.45 s |
| 4096 | 114 | 464 | 19.192 | 182.35 s |
| 8192 | 228 | 233 | 9.700 | 442.14 s |
| 16384 | 456 | 117 | 4.898 | 154.01 s |
| 27036 | 751 | 71 | 2.988 | 276.20 s |
Les tableaux suivants (tableau 2, tableau 3, tableau 4 et tableau 5) présentent la forte mise à l'échelle d'EFISPEC3D sur les instances C5n et M5zn :
| Number of cores | Blocking communications | Non-blocking communications |
| 1 | 2542.38 s | 2522.54 s |
| 32 | 92.13 s | 106.09 s |
| 64 | 45.19 s | 47.50 s |
| 128 | 22.79 s | 24.93 s |
| 256 | 12.18 s | 12.51 s |
| 512 | 6.66 s | 6.63 s |
| 1024 | 3.57 s | 3.34 s |
| 2048 | 2.17 s | 1.60 s |
| 4096 | 1.43 s | 0.79 s |
| 8192 | 1.74 s | 0.40 s |
| 16384 | – | 0.20 s |
| 27036 | – | 0.14 s |
| Number of cores | Blocking communications | Non-blocking communications |
| 1 | 1.0x | 1.0x |
| 32 | 27.59x | 23.78x |
| 64 | 56.26x | 53.10x |
| 128 | 111.56x | 101.19x |
| 256 | 208.79x | 201.67x |
| 512 | 381.94x | 380.59x |
| 1024 | 711.14x | 754.92x |
| 2048 | 1171.72x | 1576.72x |
| 4096 | 1782.18x | 3187.30x |
| 8192 | 1457.32x | 6339.85x |
| 16384 | – | 12484.81x |
| 27036 | – | 18030.57x |
| Number of cores | Number of instances | Blocking communications | Non-blocking communications |
| 1 | 1 | 2026.03 s | 2027.19 s |
| 32 | 2 | 50.25 s | 54.49 s |
| 64 | 3 | 33.28 s | 36.82 s |
| 128 | 6 | 16.77 s | 17.70 s |
| 256 | 11 | 9.47 s | 9.56 s |
| 512 | 22 | 4.77 s | 4.91 s |
| 1024 | 43 | 2.98 s | 2.49 s |
| Number of cores | Blocking communications | Non-blocking communications |
| 32 | 40.31x | 37.20x |
| 64 | 60.88x | 55.06x |
| 128 | 120.82x | 114.51x |
| 256 | 213.94x | 211.99x |
| 512 | 424.32x | 413.09x |
| 1024 | 680.74x | 812.20x |
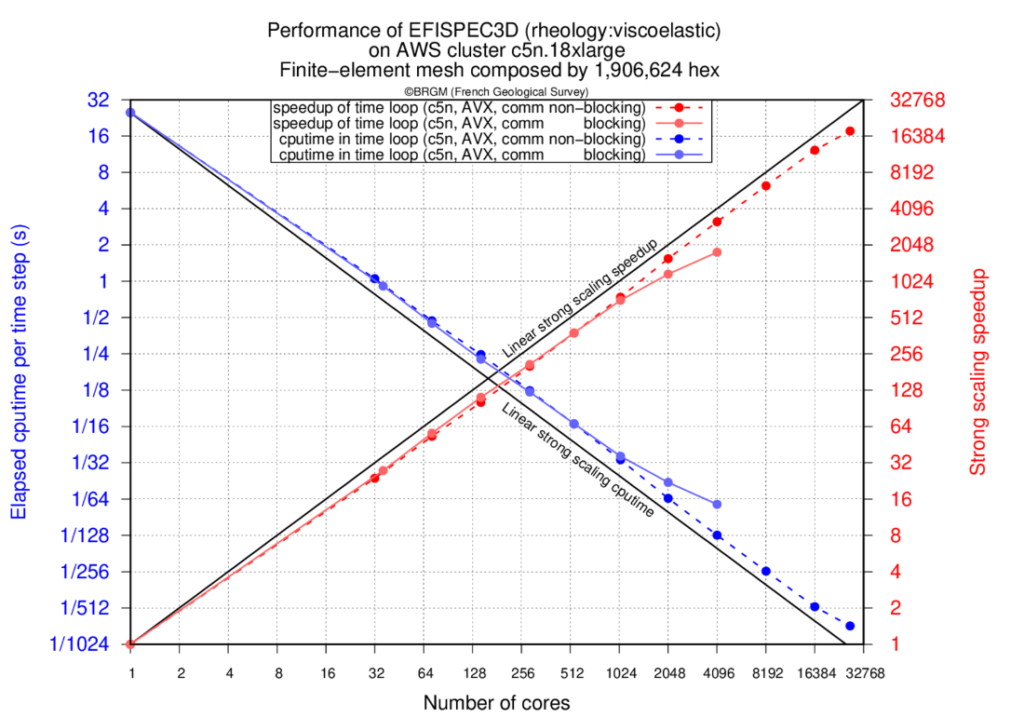
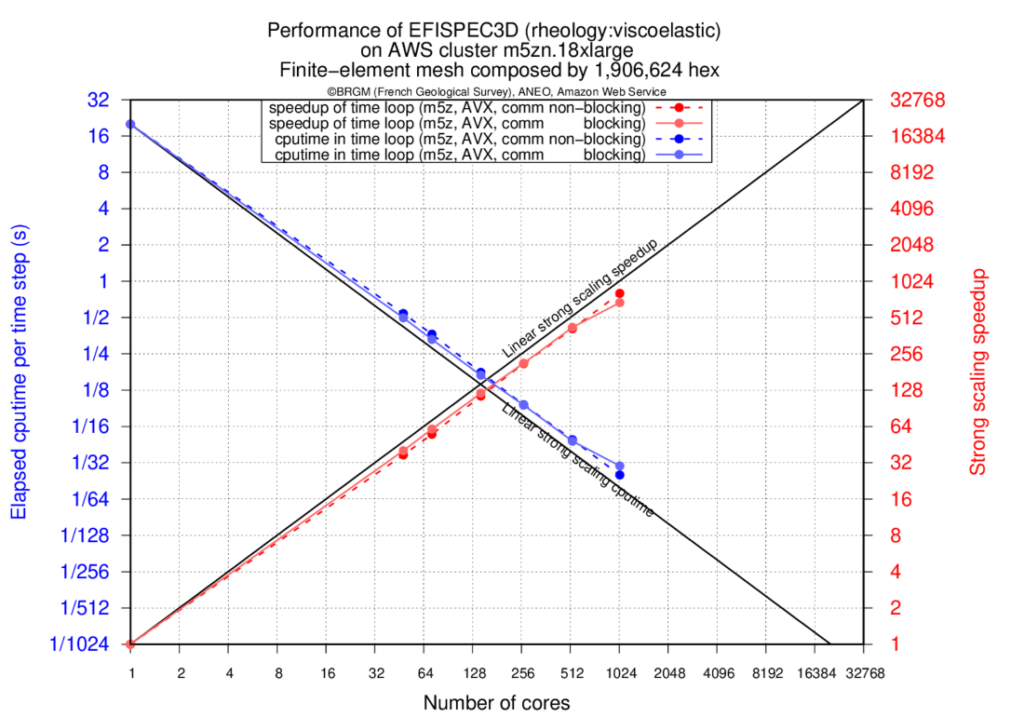
Les résultats présentent les temps écoulés pour le calcul de la boucle temporelle (en secondes) d'EFISPEC3D en utilisant des communications bloquantes ou non bloquantes, et les accélérations obtenues par rapport à la simulation effectuée sur un seul cœur physique. Nous pouvons remarquer que la forte mise à l'échelle sur le cluster d'AWS avec EFA est de 67% à 27036 cœurs, plus particulièrement pour la version avec communications non-bloquantes pour laquelle un accroissement de vitesse de 18030 est atteint sur 27036 cœurs physiques (voir Figure 1). Une telle accélération permet de calculer une simulation de tremblement de terre standard en environ 25 minutes au lieu de 300 jours sur un seul cœur.
Lorsque des communications bloquantes sont utilisées, nous pouvons voir la baisse de performance autour de 2048 cœurs en raison du temps incompressible d'envoi et de réception des appels MPI. En chevauchant les communications avec les calculs, la baisse de performance est repoussée jusqu'à 27036 cœurs.
Simulations d'hexaèdres 7M
Lors de cette seconde expérience, nous avons activé la lecture et l'écriture sur le système de fichiers « Amazon FSx for Lustre » dans l'application EFISPEC3D car elle utilise l'écriture de données via Intel MPI. Nous avons ensuite choisi de vérifier les performances d'Amazon FSx for Lustre.
L'objectif était de tester les performances de l'écriture de résultats sur un système de fichiers lorsque 2048 tâches écrivent des résultats sur le système de fichiers en même temps. Pour ce test, nous avons utilisé un cluster de 57 instances c5n.18xlarge (total de 2052 cœurs).
L'exécution de l'application génère 2 To de données, principalement condensées dans un seul fichier. La configuration des performances du système de fichiers est basée sur deux paramètres principaux : le facteur de taille de bloc et le facteur d'effacement. Il s'agit respectivement de la taille des paquets de données à écrire et du nombre de paquets à écrire simultanément par l'application. La configuration du système de fichiers permet de calibrer l'écriture optimale sur disque en adéquation avec la taille d'écriture par l'application et le nombre de lignes d'écriture autorisées par le système de fichiers.
Pour permettre l'analyse des performances de plusieurs configurations du système de fichiers, nous avons réduit la taille du fichier à 206 Go. Cette procédure nous a permis d'évaluer beaucoup plus de configurations différentes du système de fichiers Amazon FSx for Lustre tout en préservant la fiabilité des résultats de performance obtenus.
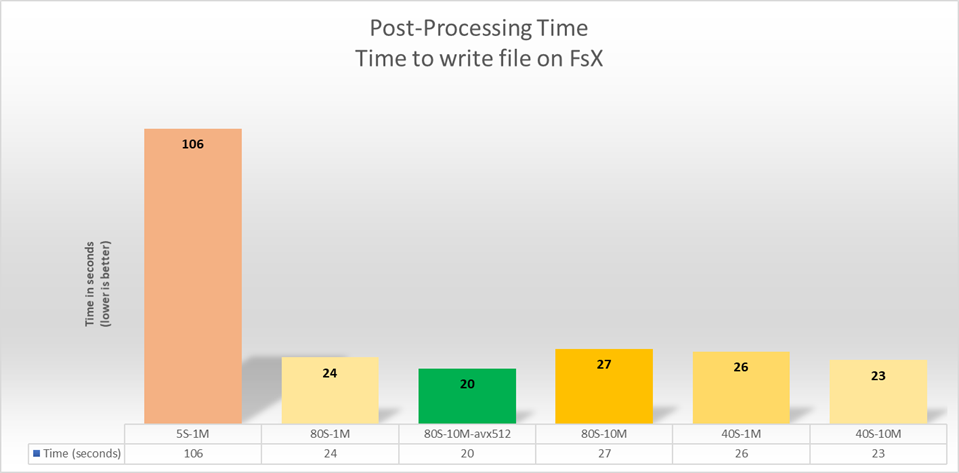
Impact des paramètres du système de fichiers. Lustre sur la bande passante mesurée pour la phase de lecture des données (206GB). La taille des bandes varie de 1MB à 10MB et le facteur de striping varie de 5 à 80.
Dans le graphique de la figure 3, chaque bâton représente une exécution avec différentes configurations d'Amazon FSx pour les paramètres Lustre. Par exemple, 5S - 1M signifie que le test a été calibré avec un facteur de 5 bandes et 1 mégaoctet comme taille de bloc de données.
Ces tests ont été effectués en utilisant un volume FSx for Lustre de 96 To avec 80 OSD. Le type de déploiement "Scratch 2" ou FSx pour Lustre a été utilisé. Ce système de fichiers offre une performance théorique de 200 Mo par To + 1,3 Go/s de bande passante en rafale. Le système de fichiers tel qu'il a été déployé avait une performance de base de 16 Go/s avec une capacité de rafale de 104 Go/s
Suite à ces six exécutions, nous constatons que les meilleures performances seront atteintes avec EFISPEC3D lorsque nous définissons le système de fichiers avec un facteur de dédoublement de 80 et des tailles de blocs de 10 mégaoctets.
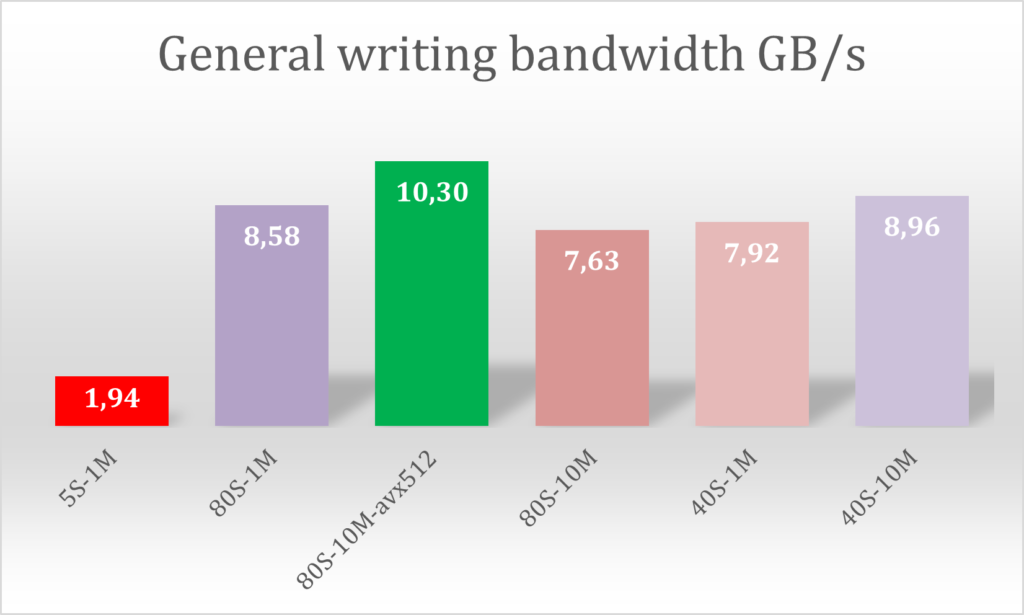
Pendant les phases de post-traitement de l'application EFISPEC3D, la bande passante a atteint 10,3 Go/s pour écrire un fichier de résultats de 206 Go.
Étude des coûts publics jusqu'à l'exécution de 7 millions d'euros
Nous avons étudié le coût d'exécution de l'application EFISPEC3D sur la simulation de 7 mégas hexaèdres. Basé sur les prix publics d'AWS proposés dans la région américaine de Virginie.
Pour rappel, l'infrastructure choisie est basée sur les 2048 cœurs physiques de l'instance c5n.18xlarge et ses 72 vCPUs de processeur Intel® Xeon® Platinium. Cela signifie que nous avons pu démarrer 57 instances de c5n.18xlarge dans la même Région, à savoir la Région us-east-1.
Le coût total de ces instances pour 25 minutes s'élève à un prix public de 93$. Dans l'infrastructure choisie, nous utilisons également le système de fichiers FSx pour 30 $ par jour et par cluster déployé pour 3,6 To de stockage.
Au total, le coût du cluster pour ce type d'exécution s'élève à 123$ de prix public pour l'exécution d'une application pendant 25 minutes avec 57 instances de c5n.18xlarge.
Conclusion
Au cours de la phase de R&D et d'analyse comparative, nous avons pu constater à quel point il est facile de déployer, d'installer et de configurer notre environnement HPC en utilisant AWS ParallelCluster,
un outil de gestion de clusters open source soutenu par AWS qui facilite le déploiement et la gestion de clusters HPC (High Performance Computing) sur AWS. Nous avons également constaté la rapidité avec laquelle les instances C5n sont disponibles dans toutes les régions AWS du monde. Les instances M5zn sont très différentes à plusieurs égards. Elles ont moins de cœurs plus rapides et sont basées sur l'architecture Intel Cascade Lake. Plus de 400 types d'instances sont disponibles sur AWS. Comme toujours avec les applications HPC, il n'y a pas de substitut pour tester l'application réelle et les données afin de voir quels systèmes offrent la meilleure combinaison de coûts et de performances pour une application donnée.
Lors des tests de mise à l'échelle, nous avons pu observer de très bonnes performances de l'application EFISPEC3D, ce qui démontre la puissance des serveurs C5n et M5zn pour le monde HPC.
En ce qui concerne le système de fichiers Amazon FSx for Lustre, nous avons atteint une bande passante supérieure à 10 Go/s, ce qui a largement répondu aux exigences de notre application avec une écriture intensive sur le disque par tous les nœuds de calcul.
EFISPEC3D est présenté dans un atelier HPC. L'atelier guide l'utilisateur dans le processus de déploiement d'un cluster HPC et d'exécution du logiciel EFISPEC3D. Il est disponible à l'adresse suivante :
https://hpc.news/efispec3dworkshop
Pour plus d'informations sur EFISPEC3D, cliquez ici :



